Cloud Native Patterns: Designing Change-tolerant Software
1. Cloud-Native (CN) Software
- Cloud-native software
- Cloud is about where we are computing. Cloud-native is about how.
- It’s resilient against changes (redundant).
- Smaller, loosely coupled and independent services that can be released in an agile method.
- Scales dynamically and continues to function adequately.
- It must be distributed to protect against failure.
- It should adapt to changes.
Cloud-native software is highly distributed, must operate on a constantly changing environment, and is itself constantly changing.
- Familiar elements of a basic software architecture
- App implements key business logic.
- The App depends on Services, which may store business logic or data.
- An App depends on multiple services, which depend on other services.
- Some apps depend on stateful services.
- Apps will have most of the time many instances deployed
- Some services are stateless, whereas others are stateful.
The Three Parts of Cloud-Native Software
- The cloud-native app is where you write code, containing the business logic of your software.
- The right patterns should be used for each component to integrate well with each other.
- It should be constructed in a manner that allows cloud-native operational patterns such as upgrading or scaling to be performed.
- Cloud-native data is where the state lives in your cloud-native software. Data (and databases) are decomposed and distributed.
- Cloud-native interactions define how cloud-native apps and cloud-native data interact - many of these patterns are new. They may be request/response, push-centric or pull-centric.
Cloud-Native Apps Concerns
- Their capacity is scaled up or down by adding or removing instances (scale-out/in).
- Keep the state separated from the apps for faster recovery (resilience).
- Configuration has to be shared between distributed deployments.
- The application lifecycle (start, configure, reconfigure and shutdown) must be re-evaluated in this context.
Cloud-Native Data Concerns
- Centralized data models are slow to evolve, brittle and affects the agility and robustness of loosely coupled apps.
- The distributed data fabric is made of independent, fit-for-purpose databases, as well as some that may be acting only as materialized views of data, where the source of truth lies elsewhere.
- Caching is a key pattern and technology in cloud-native software.
Cloud-Native Interactions
- Accessing an app when it has multiple instances requires a routing system.
- Synchronous request/response and asynchronous event-driven patterns must be addressed.
- Automatic retries and circuit breakers must be taken into account.
2. Running Cloud-Native Applications in Production
- Factors that contribute to the difficulty in deploying software and keeping it running well in production:
- Snowflakes: difference between environments and artifacts being deployed (“it works on my machine!”).
- Risky deployments: often deployments require or cause downtime.
- Change is the exception: the app is considered stable and simply handed over to an operations team.
- Production instability: an unstable production environment makes deployments harder to make.
- Factors that develop a system of efficiency, predictability, and stability.
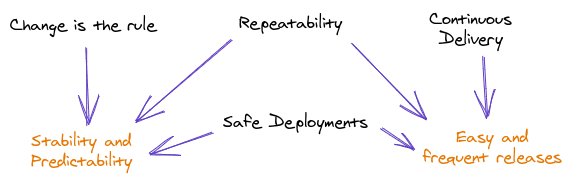
Continuous Delivery
- Frequent releases drive business agility and enablement, which indicate strong organization.
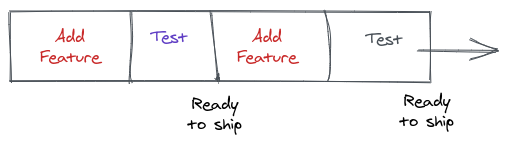
- An as-new-as-possible version of the software is deployable at any time.
- Faster release cycles allow you to collect feedback more often and react on them.
Repeatability
- The outcome of a process (e.g. a deployment or a build) is predictable.
- To achieve it, we need to:
- Control the environment: “infrastructure as code” and standardized machine images give you better control.
- Control the deployable artifact: a single deployable artifact should be used on the entire SDLC.
- Control the process: the entire SDLC should be controlled and automated.
Safe deployments
- With this new mindset, you plan for failure and setup ways to deal with them.
- Telemetry should be used to collect system stats.
- Componentization of applications reduces risk.
Change is the rule
- You need to let go the notion of ever being done.
- Systems should be design to be self-healing to adapt to the constant change inflicted upon it.
3. The Platform for Cloud-Native Software
- Leverage IaaS (Infrastructure as a Service) to focus on the application.
- It enables easier consumption of compute, storage, and network abstractions, leaving the underlying management of hardware to the provider.
Core Tenets of the Cloud Native Platform
- Containers: they are a computing context that uses functionality from a host that it’s running on.
- Support for “constant changes”: eventual consistency.
- Support for “highly distributed”: service discovery, service configuration and distributed tracing.
Platform Capabilities
- The platform support the entire SDLC (software development lifecycle)
- A single deployable artifact that carries through the SDLC is essential.
- Having environment parity is essential to the continuous delivery process.
- Security, change-control, compliance
- The platform must provide security, compliance, and change-control assurance.
- Controlling what goes in the container
- The platform should allow only approved base images to be used.
- The platform should control all runtime envs that may be included in a container.
- Build pipelines coupled with code scans provide automation to repeatably and safely create the artifact.
- Upgrading and patching vulnerabilities
- Platform supports rolling updates.
- Change-control
- Platform provides means of insulating components from one another, so problems in one part of the data center will be kep from impacting others.
4. Event-Driven Microservices
- Request/response interaction establish a direct dependency between services. Consuming and producing events can be done independently.
- You must apply the request/response and the event-driven approaches when appropriate.
Event-driven Computing
- The entity that triggers code execution in an event-driven system does not expect any kind of response.

- Event and outcome are entirely disconnected.
- On an event-based design, services are proactively sending out change notifications rather than waiting to be asked.
- State changes are persisted by consumers if needed. This way, the consuming service will not depend directly on the producing service.
Command Query Responsibility Segregation (CQRS)
- Separating read and write operations allows each of them to have its own model. Though some properties may exist in both, others are only meaningful on only one side or the other.
- Write logic: COMMAND
- Read logic: QUERY
- This separation offers flexibility on how each part is used (e.g. HTTP, event-based, websockets).
5. App Redundancy: Scale-out and Statelessness
- Given the same input, the result produced by an app instance must be the same, regardless of whether there are one, two or one hundred instances of the app.
- Cloud-native apps have many instances deployed.
- Scale is achieved by adding or removing app instances.
Stateful Apps in the Cloud
- A common way for state to creep in is through session state. Each app instance would have its own session state and create problems.
Stateful services and stateless apps
- Cloud-native apps have places where state lives, and just as important, places where it does not.
- External storage should be used to store state (e.g. Redis). Those are the so-called stateful services.
6. Application Configuration
- The cloud-native context for configuration is new.
- App configuration changes are often brought from changes in the infrastructure, which are either anticipated or expected.
- Configuration may be needed to be updated with zero downtime.
- Therefore, a tested and repeatable way must be found to reach these requirements.
- Applications should define configurations on an application configuration layer, but the configuration should be stored on the environment (12-Factor App).
Injecting Application Configuration
- Configuration data should be persisted and access controlled.
- Configurations data should not be applied by hand.
- Configurations must be versioned.
- A config store or server can be used to hold the configuration (e.g. Hashicorp Vault).
7. Application Lifecycle
-
It is about the stages an application goes through after it is ready for production deployment.
-
Operational Concerns
- Manageability: whenever possible, management functions should be automated, and when any tasks are necessary, they should be done efficiently and reliably.
- Resilience: the platform has a fail-safe way of detecting when an app has failed.
- Responsiveness: users of your software must receive outputs in a timely manner.
- Cost management: you are able to use only the resources you need at the moment (scaling).
-
You must design your apps and document the API so that any lifecycle events that have an impact on dependent services are eliminated, are minimized, or can be adapted to by those clients.
-
Write your logs to
STDOUTandSTDERRand treat them as an event stream. -
Apps must be built not only to work in the happy path, but also to continue working, or self-heal when things go awry.
- Health check and responders play a critical role.
- On Kubernetes:
ReadinessProbeandLivenessProbe.
8. Accessing Apps: Services, Routing and Service Discovery
- In cloud-native software, apps are deployed as multiple instances. For the software to function predictably, you want each set of app instances to operated as a single logical entity.
- Your software is defined as a composition of services, each of them implemented as a set of instances.

- Services are found via Service Discovery. When a request comes to the service, they are routed to the instances. This is done via Dynamic Routing.
- Dynamic routing can be achieved via server-side (most common) or client-side load-balancing.
- Route-freshness is provided by the platform control-loop, which assesses the instances state through health endpoints/probes.
- Service discovery allows a client to refer to a service by name, resulting in a more resilient binding between them,
- Naming systems are set up for availability. Clients have to implement compensating behaviors when there are consistency failures (e.g. retries). This is called Eventual Consistency.
- Kubernetes offers service discovery via a component called CoreDNS. When a service is registered, DNS registration is automatically made by k8s.
9. Interaction Redundancy: Retries and Control Loops
Request Retries (client)
- Components will fail, but we can achieve resilience by adapting to that inevitable disruption.
- Basic retry: when a request fails, retry it. In certain cases, this will cause retry storms, which can be mitigated. You can limit the number of retries, their interval or apply an algorithm such as exponential backoff.
- Only safe HTTP methods should be retried (
GET,HEAD).
Fallback Logic (client)
- One of the most fundamental patterns in designing for failure is to implement fallback methods.
- Example: cache the last successful response, and use it when a certain call fails. This way, trouble in one part of your software will not cascade through the distributed system.
Control Loops (server)
- The control loop never expected to reach a “done” state, and is designed to be constantly looking for the inevitable change and to response properly.
- In k8s: controllers.
10. Fronting Services: Circuit Breakers and API Gateways
Circuit Breakers
- They protected a service from unusual amounts of traffic. If a service starts to fail, you stop all traffic for a while. After some time, you let a single response through, to check if it has recovered. If so, then traffic flows again freely, otherwise you wait a bit more.
- They move between three states:
- Closed: traffic flows freely.
- Open: traffic is blocked.
- Half-open: only a single or a small quantity of requests go through.
API Gateways
- They provide a diverse set of services, such as authentication and authorization, logging and load protection.
- An API gateway can front all services and become the policy configuration and enforcement point for them.
Service Mesh
- Sidecars: are processes that run along your main service, and provides services (e.g. API gateways).
- In k8s, this can be achieved by running two containers in the same pod, where one is the primary service and the other the sidecar.
- Envoy is a good example.
- A service mesh encompasses the set of interconnected sidecars and adds a control plane for management of those proxies. The most widely mesh used today is Istio.
11. Troubleshooting: Finding the Needle in the Haystack
Application Logging
- Logs should be sent to
STDOUTandSTDERR. - K8s allows you to get logs aggregated by labels:
kubectl logs -k app=posts - It is even better to use a platform for handling logs, such as the ELK stack.
Application Metrics
- App metrics are needed for holistic application monitoring.
- Metrics an be exported out of the app in two ways:
- Pull-based approach: a metrics aggregator is implemented as a collector that requests metrics data from each of the app instances. Each app implements a metrics endpoint that is scrapped in regular intervals (e.g. Prometheus).
- Push-based approach: each app is responsible for delivering metrics to a metrics aggregator at a regular interval.
Distributed Tracing
- It is about tracing flow across a distributed set of components.
- The core of the technique is inserting “tracers” into requests and responses, and a control plane that uses them to assemble a call graph of the invocations.
- The tracer is then included in any metrics or log output.
- Tools are used to aggregate and analyse data (e.g. Zipkin).
12. Cloud-native Data: Breaking the Data Monolith
- Every microservice needs a cache.
- Cache increases software resilience (a service will not fail if a dependant service fails) and speed.
- Caching approaches:
- Look-aside caching: the cache client implements the cache protocol.
- Read-through caching: the service accesses only the cache, which implements the logic for fetching data from the downstream service.
- Moving from request/response to event-driven
- When changes occur in downstream services, events describing those changes are sent to the interested parties.
- The cache somewhere could be expired by an event.
- The event log
- Instead of sending the events directly to a service, they are sent to an event log, which retains the events until they are no longer needed.
- Events are produced into and consumed from the event log, effectively decoupling services from one another.
- In the event-based model, the source of truth is a dedicated database to store data owned by the service.
- Topics versus queues: on queues, a single message will be processed by only one of the subscribers; in a topic, the messages are sent to all subscribers, being processed by any number of them.
- Event handlers should be idempotent.
- Event sourcing
- The source of truth for all data is the event store/log. In event sourcing, all sources of record data writes are made only to the event store, and all other stores are simply holding projections or snapshots of state derived from the events stored in the event log.